Python/強化学習初心者が四目並べ作ってみた¶
2019/02/16 Takano
自己紹介¶
- 高野 剛
- 産業機器メーカ勤務
- ソフト担当範囲:ハードウェア・カーネル周り
- C/C++ がメイン、 Perl/Ruby を少々
やりたいこと¶
- AIを使って囲碁・将棋でとても強くなった
- その仕組を知りたくなった
- python, 強化学習をやってみたい <== イマココ
- 強いボードゲームを作りたい <== 目標
四目並べルール¶
- 盤面サイズは NxN (N = [7, 15])
- 禁じ手(五目並べの 3x3禁)は考えない
- 最初の1手は盤面中央に固定する
- 二手目以降は石の周辺のみ着手可能
TD学習¶
状態
- NxN 盤面を N次元ベクトル表現で表し、状態とした
- それぞれの着手による変化を状態変化とした
報酬
- NxN 盤面で X手で勝った時、 NxN - X の報酬
(単手数で勝ったほうが良い)
- NxN 盤面で X手で負けた時、 -NxN + X の報酬
(粘って負けたほうが良い)
- 引き分けの時、報酬0
方策
- 探索時は有効手からランダムで選択する
- 利用時は最大価値の局面を選択する
学習1¶
- ランダムPlayer(先手) vs AI Player(後手)
- 1イテレーションを 5,000局 とした
- 探索係数?は 0.1
- ステップサイズは 0.2
- 9x9 盤面だと学習が進まないため、7x7 盤面とした
- 7x7 盤面の時、ランダムに石を並べると先手勝率 60%
結果1¶
- 後手番勝率が 90% 程度に改善した
- 90%以降の勝率改善はほぼなかった
- 遊んでみるとメチャクチャ弱い
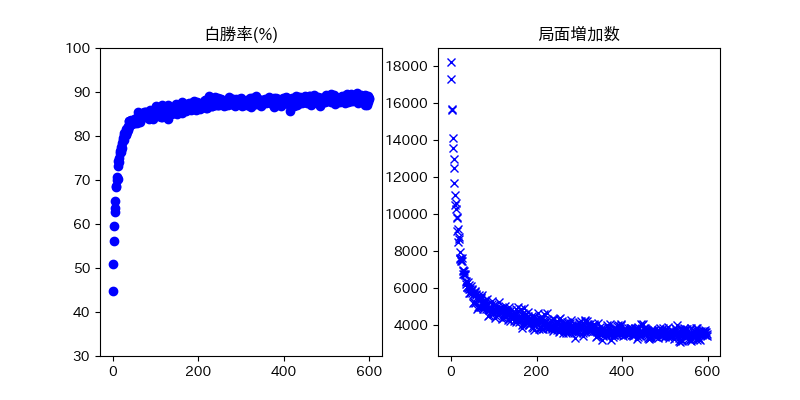
- 探索局面の広がりが狭い事が原因と推測
- 8手目の有効盤面数は約138万通り
- うち、7万通りを発見した
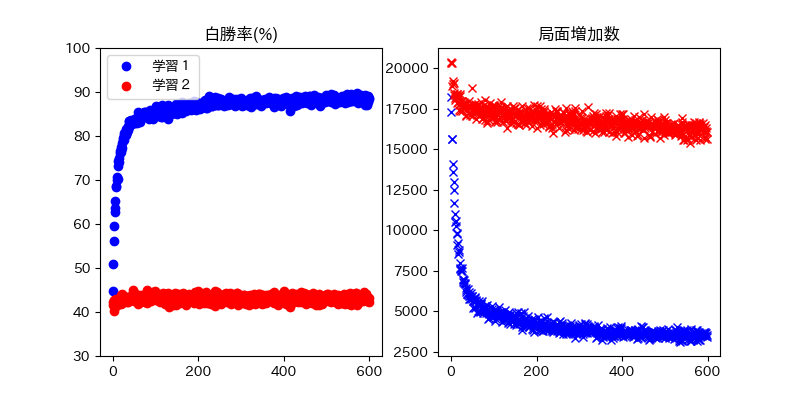
結果2¶
- 勝率は横ばい
- 探索局面は広くなった
- 8手目の有効盤面数は約138万通り
- 約75万局を発見した
学習後のPlayer と対戦してみた¶
- 一応、それらしい動きはするようになった
- 防御の手は発見できない
- 相変わらず弱い
後手番で対戦してみます?¶
むすび¶
- TD学習は総当たりの辞書を作っているだけなので、強い状態にはならないのだろう
- MCTS などを使えば効率は改善するのかもしれない
- 4目並べの性質を理解する何かを入れないと遊べる強いPlayer にはならないのだろう
- 早いPC って大事。。。処理効率の改善が大半の時間を占めた
- python sugeeee :-)